通常程序会被编写为一个顺序执行并完成一个独立任务的代码。如果没有特别的需求,最好总是这样写代码。
但是有些情况并行执行多个任务会有更大的好处。比如说: Web 服务需要在各自独立的套接字(socket)上同时接受多个请求数据。每个套接字请求都是独立的,可以完全独立 于其他套接字进行处理。具有并行执行多个请求的能力可以显著提高这类系统的性能。
Golang 中并发指能让某个函数独立于其他函数运行的能力 。
当一个函数创建 goroutine 时,Golang 会将其视为一个独立的工作单元。这个单元会被调度到可用的逻辑处理器上执行。
运行时调度器能管理被创建的所有 goroutine 并为其分配执行时间 。在任何给定的时间,全面控制哪个 goroutine 在哪个逻辑处理器上运行。
Golang 语言的并发同步模型来自一个叫做通信顺序进程 (Communicating Sequential Processes, CSP)的范型。
CSP 是一种消息传递模型,通过在 goroutine 之间传递数据来传递消息,而不是对数据进行加锁来实现同步访问。用于在 goroutine 之间同步和传递数据的关键数据类型叫通道 。
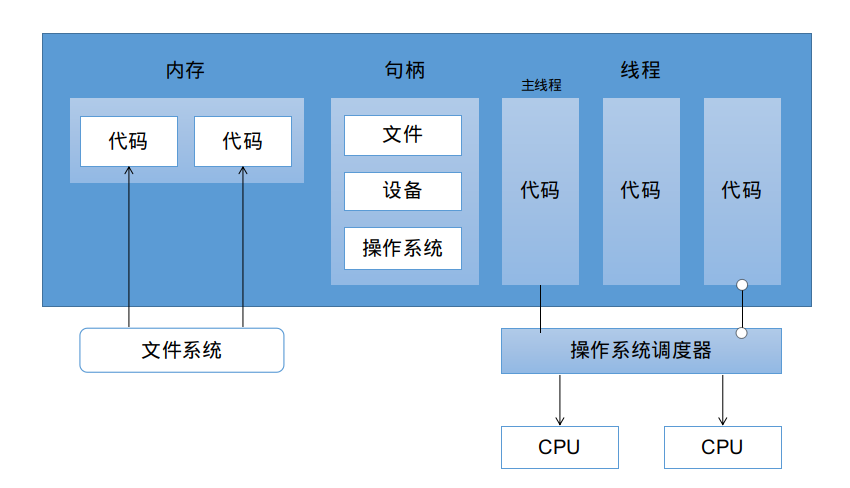
并行和并发 什么是进程 和线程 当运行一个应用程序的时候,操作系统会为这个应用程序启动一个进程。可以将这个进程看做一个包含了应用程序在运行中需要用到和维护的各种资源的容器。
上图展示了一个包含所有可能分配的常用资源的进程。这些资源包括但不限于 : 内存地址空间、文件和设备的句柄以及线程。
一个线程是一个执行空间,这个空间会被操作系统调度来运行函数中所写的代码。
每个进程至少包含一个线程,每个进程的初始化线程会被称作主线程 。
操作系统将线程调度到某个处理器上运行,这个处理器不一定是进程所在的处理器。
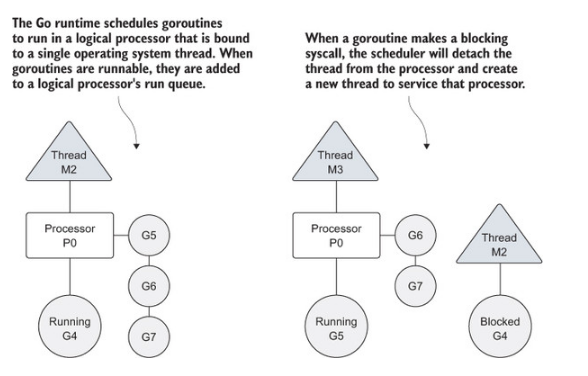
操作系统会在物理处理器上调度线程来运行,而 Go 语言的运行时会在逻辑处理器上调度 goroutine 来运行。每个逻辑处理器都分别绑定到单个操作系统线程。
上图展示了操作系统线程、逻辑处理器和本地队列之间的关系。
如果创建一个 goroutine 并准备运行,这个 goroutine 就会被放到调度器的全局运行队列中,之后调度器就将这些队列中的 goroutine 分配给一个逻辑处理器,并放到这个逻辑处理器对应的本地运行队列中。本地运行队列中的 goroutine 会一直等待直到自己被分配的逻辑处理器执行。
当正在运行的 goroutine 需要执行一个阻塞的系统调用时,比如打开一个文件,线程和 goroutine 会从逻辑处理器上分离,该线程会继续阻塞,等待系统调用的返回。榆次同事,这个逻辑处理器就失去了用来运行的线程。调度器会创建一个新的线程 ,并将其绑定到该逻辑处理器上。
当被阻塞的系统调用执行完成并返回,对应的 goroutine 会放回本地运行队列,而之前的线程会被保存好,以便之后可以继续使用。
如果一个 goroutine 需要做一个网络 I/O 调用,流程上会有些不一样。在这种情况下, goroutine 会和逻辑处理器分离,并移到集成了网络轮训器的运行时。
一旦该轮训器指示某个网络读或者写操作已经就绪,对应的 goroutine 就会重新分配到逻辑处理器来完成操作。调度器对可以创建的逻辑处理器数量没有限制,但语言运行时默认限制每个程序最多创建 10000 个线程。
限制值可以通过调用 runtime/debug 包的 SetMaxThreads 方法来更改。如果程序试图使用更多的线程,就会崩溃。
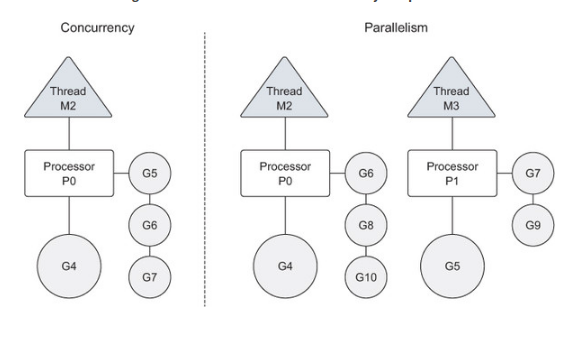
并发和并行的区别 并发是让不同的代码片段同时在不同的物理处理器上执行 ,并行的关键是同时做 很多事情,而并发是指同时管理 很多事情,这些事情可能只做了一般就被暂停去做别的事情了。
很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。这种“使用较少的资源做更多的事情”的哲学,也是指导 Go语言设计的哲学。
如果希望让 goroutine 并行,必须使用多于一个逻辑处理器,当有多个逻辑处理器时,调度器会将 goroutine 平等分配到每个逻辑处理器上。这会让 goroutine 在不同的线程上运行。
如果想真的实现并行的效果,需要让程序运行在有多个物理处理器的机器上,否则,哪怕 Go 语言运行时使用多个线程, goroutine 依然会在同一个物理处理器上并发运行,达不到并行的效果。
goroutine 调度器是如何创建 goroutine 并管理其寿命的?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package mainimport ( "fmt" "runtime" "sync" ) func main () runtime.GOMAXPROCS(1 ) var wg sync.WaitGroup wg.Add(2 ) fmt.Println("Start Goroutines" ) go func () defer wg.Done() for count := 0 ; count < 3 ; count ++ { for char := 'a' ; char < 'a' + 26 ; char++ { fmt.Printf("%c" , char) } } }() go func () defer wg.Done() for count := 0 ; count < 3 ; count++ { for char := 'A' ; char < 'A' + 26 ; char++ { fmt.Printf("%c" , char) } } }() fmt.Println("Waiting To Finish" ) wg.Wait() fmt.Println("\nTerminating Program" ) }
再看一段代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport ( "fmt" "runtime" "sync" ) var wg sync.WaitGroupfunc main () runtime.GOMAXPROCS(1 ) wg.Add(2 ) fmt.Println("Create Goroutines" ) go printPrime("A" ) go printPrime("B" ) fmt.Println("Waiting To Finish" ) wg.Wait() fmt.Println("Terminating Program" ) } func printPrime (prefix string ) defer wg.Done() next: for outer := 2 ; outer < 5000 ; outer++ { for inner := 2 ; inner < outer; inner++ { if outer%inner == 0 { continue next } } fmt.Println("%s:%d\n" , prefix, outer) } }
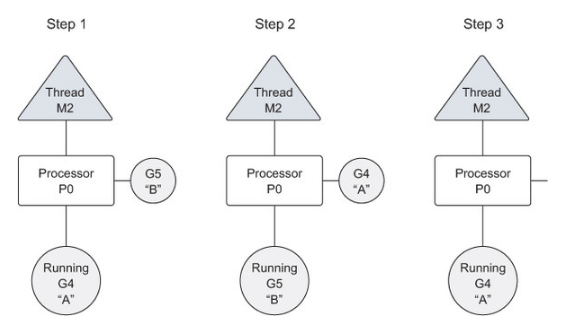
根据上图,我们可以发现,为了防止某个 goroutine 长时间占用逻辑处理器,调度器在 goroutine 占用时间过长时会停止当前运行的 goroutine,并给其他可运行的 goroutine 运行的机会。即切换时间片 。
竞争状态 什么是竞争状态 如果两个或多个 goroutine 在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这个资源,就处于互相竞争的状态。
要求 竞争状态的存在是让并发程序变得复杂的地方,十分容易引起潜在问题。对一个共享资源的读和写操作必须是原子化的。 即同一时刻只能有一个 goroutine 对共享资源进行读和写操作。
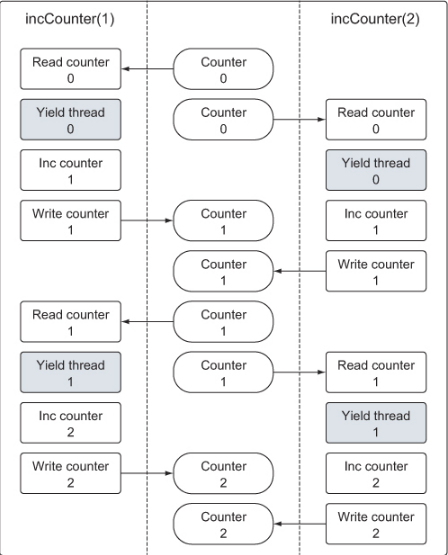
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package mainimport ( "fmt" "runtime" "sync" ) var ( couter int wg sync.WaitGroup ) func main () wg.Add(2 ) go incCounter(1 ) go incCounter(2 ) wg.Wait() fmt.Println("Final Counter:" , counter) } func incCounter (id int ) defer wg.Done() for count := 0 ; count < 2 ; count++ { value := counter runtime.Gosched() value++ counter = value } }
我们可以观潮到,总共开启了两个 goroutine ,对于变量 counter 各加两次。但最后的结果可能不是 4。
原因如下图所示:
我们可以通过一个小手段来在代码编译阶段检查竞争问题,使用命令 go build -race 可以使用竞争检测器标志来编译程序,帮助我们提前发现代码中的竞争问题。
手段 加锁 通过对共享资源加锁来保证 goroutine 的同步状态。
原子函数
如果要顺序访问一个整型变量或者一段代码, atomic 和 sync 包里的函数提供了很好的解决方案。通过原子函数,可以利用很底层的加锁机制来同步访问整型变量和指针。
我们可以将上面的代码修改成下面这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ( "fmt" "runtime" "sync" "sync/atomic" ) var ( counter int64 wg sync.WaitGroup ) func main () wg.Add(2 ) go incCounter(1 ) go incCounter(2 ) wg.Wait() fmt.Println("Final Counter:" , counter) } func incCounter (id int ) defer wg.Done() for count := 0 ; counter < 2 ; count++ { atomic.AddInt64(&counter, 1 ) runtime.Gosched() } }
互斥锁
另一种同步访问共享资源的方式是使用互斥锁(mutex ),互斥锁这个名字来自互斥的概念。互斥锁用于在代码上创建一个临界区,保证同一时间只有一个 goroutine 可以执行这个临界区代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package mainimport ( "fmt" "runtime" "sync" ) var ( counter int wg sync.WaitGroup mutex sync.Mutex ) func main () wg.Add(2 ) go incCounter(1 ) go incCounter(2 ) wg.Wait() fmt.Printf("Final Counter: %d\\n" , counter) } func incCounter (id int ) defer wg.Done() for count := 0 ; count < 2 ; count ++ { mutex.Lock() { value := counter runtime.Gosched() value++ counter = value } mutex.Unlock() } }
通道
原子函数和互斥锁都能工作,但是依靠它们都不会让编写并发程序变得更简单容易,不容易出错。
在 Golang 中,不仅可以通过使用原子函数和互斥锁来保证对共享资源的安全访问以及消除竞争状态,还可以使用通道,通过发送和接受需要共享的资源,在 goroutine 之间做同步。
当一个资源需要在 goroutine 之间共享时,通道在 goroutine 之间架起了一个管道,并提供了确保同步交换数据的机制 。
声明通道时,需要指定将要被共享的数据的类型。可以通过通道共享内置类型、命名类型、结构类型和引用类型的值或指针。
声明通道的格式如下:
1 2 3 4 unbuffered := make (chan int ) buffered := make (chan string , 10 )
向通道发送值或指针需要用到 <- 操作符:
1 2 buffered := make (chan string , 10 ) buffered <- "Gopher"
同样,从通道里接收一个值或者指针时,<- 运算符在要操作的通道变量的左侧,代码如下:
通过两个例子来系统学习一下,一个利用了无缓冲通道 ,另一个利用的有缓冲通道
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package mainimport ( "fmt" "math/rand" "sync" "time" ) var wg sync.WaitGroupfunc init () rand.Seed(time.Now().UnixNano()) } func main () court := make (chan int ) wg.Add(2 ) go player("Nadal" , court) go player("Djokovic" , court) count <- 1 wg.Wait() } func player (name string , court chan int ) defer wg.Done() for { ball, ok := <-court if !ok { fmt.Printf("Player %s Won\n" , name) return } n := rand.Intn(100 ) if n % 13 == 0 { fmt.Printf("Player %s Missed\n" , name) close (court) return } fmt.Printf("Player %s Hit %d\n" , name, ball) ball++ court <- ball } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 package mainimport ( "fmt" "math/rand" "sync" "time" ) const ( numberGoroutines = 4 taskLoad = 10 ) var wg sync.WaitGroupfunc init () rand.Seed(time.Now().Unix()) } func main () tasks := make (chan string , taskLoad) wg.Add(numberGoroutines) for gr := 1 ; gr <= numberGoroutines; gr++ { go worker(tasks, gr) } for post := 1 ; post <= taskLoad; post++ { tasks <- fmt.Sprintf("Task: %d" , post) } close (tasks) wg.Wait() } func worker (tasks chan string , work int ) defer wg.Done() for { task, ok := <-tasks if !ok { fmt.Printf("Worker: %d: Shutting Down\n" , worker) return } fmt.Printf("Worker: %d: Started %s\n" , worker, task) sleep := rand.Int63n(100 ) time.Sleep(time.Duration(sleep) * time.Millisecond) fmt.Printf("Worker: %d: Completed %s\n" , worker, task) } }
并发模式 写并发程序时,我们不得不去考虑一些问题,用最合理的方式去编写并发代码。考虑到创建线程/goroutine时,会有一些开销,导致不必要的系统消耗,我们需要使用一些小手段来减少这些消耗。
接下来我们讨论非常关键的三点:
控制程序的生命周期 管理可复用的资源池 创建可以处理任务的 goroutine 池
Runner runner 包用于展示如何使用通道来监视程序的执行时间,如果程序运行时间太长,也可以用 runner 包来终止程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package runnerimport ( "errors" "os" "os/signal" "time" ) type Runner struct { interrupt chan os.Signal complete chan error timeout <-chan time.Time tasks []func (int ) } var ErrTimeout = errors.New("received timeout") var ErrInterrupt = errors.New("received interrupt" )func New (d time.Duration) *Runner return &Runner{ interrupt: make (chan os.Signal, 1 ), complete: make (chan error), timeout: time.After(d), } } func (r *Runner) Add (tasks ...func (int ) ) r.tasks = append (r.tasks, tasks...) } func (r *Runner) Start () error signal.Notify(r.interrupt, os.Interrupt) go func () r.complete <- r.run() }() select { case err := <- r.complete: return err case <-r.timeout: return ErrTimeout } } func (r *Runner) run () error for id, task := range r.tasks { if r.gotInterrupt() { return ErrInterrupt } task(id) } return nil } func (r *Runner) gotInterrupt () bool select { case <- r.interrupt: signal.Stop(r.interrupt) return true default : return false } }
Pool 如何使用有缓冲的通道实现资源池,来管理可以在任意数量的 goroutine 之间共享及独立使用的资源。
这种模式在需要共享一组静态资源的情况(如共享数据库连接或者内存缓冲区)下非常有用。
如果一个 goroutine 需要从池里得到这些资源中的一个,它可以从池里申请,使用完后归还到资源池里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 package poolimport ( "errors" "log" "io" "sync" ) type Pool struct { m sync.Mutex resources chan io.Closer factory func () (io.Closer, error) // 标注 Pool 是否被关闭 closed bool } var ErrPoolClosed = errors.New("Pool has been closed.") func New (fn func () (io.Closer, error) , size uint ) (*Pool, error) if size <= 0 { return nil , errors.New("Size value too small." ) } return &Pool { factory: fn, resources: make (chan io.Closer, size), }, nil } func (p *Pool) Acquire () (io.Closer, error) select { case r, ok := <-p.resources: log.Println("Acquire:" , "Shared Resource" ) if !ok { return nil , ErrPoolClosed } return r, nil default : log.Println("Acquire:" , "New Resource" ) return p.factory() } } func (p *Pool) Release (r io.Closer) p.m.Lock() defer p.m.Unlock() if p.closed { r.Close() return } select { case p.resources <- r: log.Println("Resource:" , "In Queue" ) default : log.Println("Release:" , "Closing" ) r.Close() } } func (p *Pool) Close () p.m.Lock() defer p.m.Unlock() if p.closed { return } p.closed = true close (p.resources) for r := range p.resources { r.Close() } }
Work 通过 work 包,使用无缓冲通道来创建一个 goroutine 池,这些 goroutine 执行并控制一组工作,让其并发执行。
在这种情况下,使用无缓冲的通道要比随意指定一个缓冲区大小的有缓冲通道好,因为这个情况下既不需要一个工作队列,也不需要一组 goroutine 配合执行。
无缓冲通道保证两个 goroutine 之间的数据交换。
这种使用无缓冲的通道的方法允许使用者知道什么时候 goroutine 正在执行工作,而且如果池里的所有 goroutine 都忙,无法接受新的工作的时候,也能及时通过通道来调用通知者。
使用无缓存的通道不会有工作在队列里丢失或者卡住,所有的工作都会被处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package workimport "sync" type Worker interface { Task() } type Pool struct { work chan Worker wg sync.WaitGroup } func New (maxGoroutines int ) *Pool p := Pool { work: make (chan Worker), } p.wg.Add(maxGoroutines) for i := 0 ; i < maxGoroutines; i++ { go func () for w := range p.work { w.Task() } }() } return &p } func (p *Pool) Run (w Worker) p.work <- w } func (p *Pool) Shutdown () close (p.work) p.wg.Wait() }